

Yahoo Finance gibt es schon seit geraumer Zeit und ist die Nachrichtenholding des Web-Giganten, der auf den Namen Yahoo! hört.
Um diese Seite zu scrapen, bieten wir unsere Dienste jeder Person an, die die Extraktion von Daten umsetzen möchte. Information ist eine Form der Errungenschaft und diese bieten wir Ihnen an.
Aber, es ist für alle und jeden Benutzer zu beachten, dass dieser Artikel nur für den Zweck des Wissens und der Bildung gedacht ist, und deshalb fördern wir bei de.scrapingpass.com diese Art von Aktivität nicht unter illegalen Umständen.
Was ist Yahoo Finance?
- Es hat eine Sammlung von verschiedenen Arten von Berichten, Kommentaren, Veröffentlichungen, Nachrichten, Zitate, auf dem Finanzmarkt und die aktuelle Wirtschaft und auch, enthält alle Arten von Analysen des Marktes und Zitate von Top-Analysten, die schon seit ziemlich langem und auch, wissen ihren Weg rund um den Markt.
- Zusammen mit all diesen Informationen enthält Yahoo Finance auch einige spezielle Tools für seine Nutzer, die finanzielle Unterstützung und Management suchen.
- Das Besondere an Yahoo! Finance ist, dass alle Informationen kategorisiert, sortiert und in tabellarischer Form dargestellt sind.
- Diese Informationen können leicht in Form eines Web-Crawlers, der im Scraping-Prozess verwendet wird, implementiert werden, was sehr nützlich sein kann, um zu sagen, ob die Informationen, die benötigt werden oder das Ziel, das benötigt wird, erfüllt ist oder nicht.
- Obwohl dies eine sehr einfache Aufgabe zu sein scheint, bei der nicht viel zu tun ist, erfordert sie tatsächlich große Schritte zusammen mit der richtigen Implementierung von Web Scraping.
Python Libraries To Scrape Data From Yahoo Finance :
Hier sind einige der berühmtesten Open-Source-Bibliotheken, die von uns im Falle der Umsetzung der genannten Aufgabe des Web-Scraping von Yahoo Finance verwendet werden, und Sie können mehr hier überprüfen:
- Beautiful Soup ist ein sehr bekanntes und vertrauenswürdiges Produkt. Daher ist es das perfekte Tool für jeden Benutzer, der Informationen aus XML- oder HTML-Dateien scrapen und auf seinem Gerät speichern möchte.
- Requests ist auch ziemlich gut und ist verantwortlich für die korrekte Abfrage der HTTP-Aufrufe und auch die korrekte Verwaltung der Antwort auf eine effiziente und saubere Weise.
7 Schritte zum Scraping von Finanzdaten von Yahoo :
1. Der Benutzer muss sicherstellen, dass die Bibliotheken bereits installiert sind und keine Verzögerung eintritt.
Dies liegt daran, dass der Benutzer im Falle einer Verzögerung mit Fehlern umgehen muss, die für den gesamten Scraping-Prozess schädlich sein können, und daher sollte der folgende Code implementiert werden:
pip install requests pip install beautifulsoup4
2. Es ist notwendig, einen großen Blick auf die Webseite zu werfen, die der Benutzer versucht, zu scrapen und Informationen auf eine allgemeine Art und Weise zu sammeln.
Um ein Verständnis für die HTML-Struktur der gesamten Webseite zu bekommen, ist es notwendig, dass die Person, die an der Aktivität beteiligt ist, das Element inspiziert.
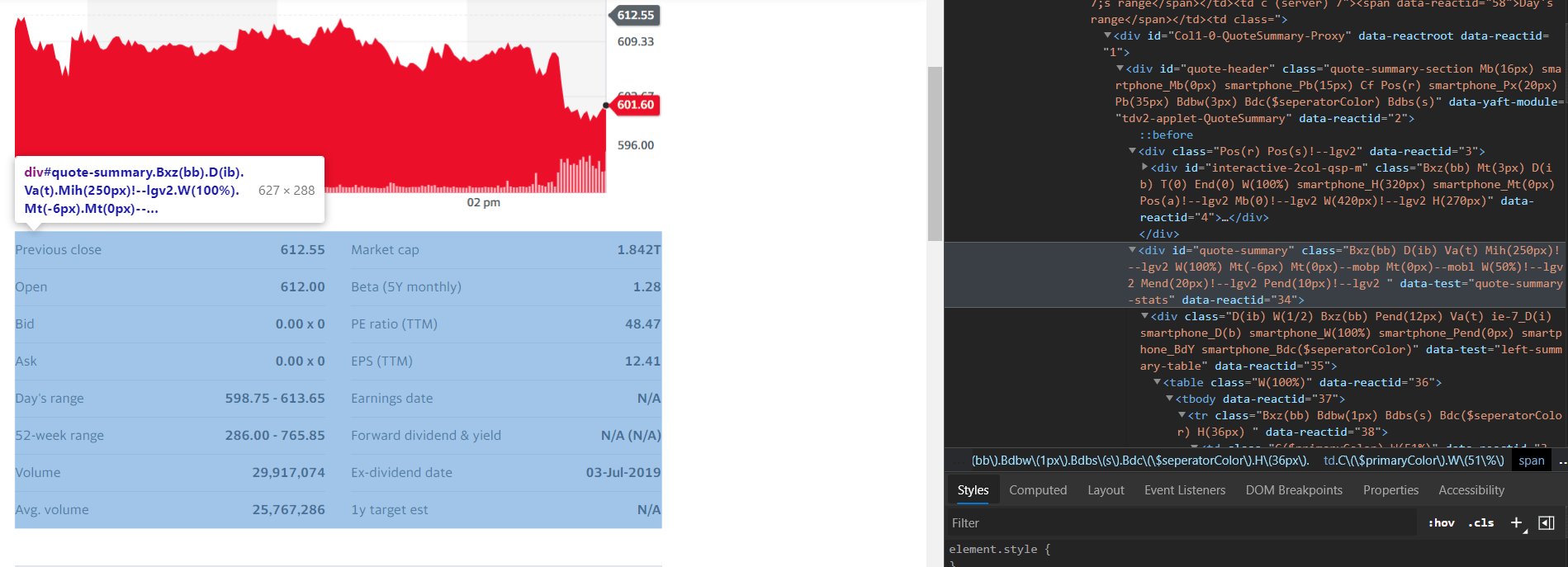
3. Anfragen Bibliothek kann leicht gemacht werden, um die erforderlichen Daten von der Website zu erhalten, dass der Benutzer braucht und der beste Teil ist, dass nicht viel komplexe Codierung benötigt wird, sondern ein viel einfacher Code von ein paar Zeilen erforderlich ist.
So wird der grundlegende Schritt für jede Art von Scaping-Prozess gemacht. Der Benutzer muss die erforderliche URL importieren, um einen Container mit der Bezeichnung “URL” abzurufen.
import requests from bs4 import BeautifulSoup url = 'https://in.finance.yahoo.com/quote/AXISBANK.NS?p=AXISBANK.NS&.tsrc=fin-srch' page = requests.get(url)
4. Der nächste Schritt ist nun das Parsen des extrahierten Textes in HTML-strukturierte Daten. Hier kommt die beautifulsoup-Bibliothek ins Spiel, die der Anwender im Prozess des Scrapings implementieren wird.
Auch dieser Schritt kann in wenigen Zeilen Code erledigt werden, wie unten gezeigt:
soup = BeautifulSoup(page.text, 'html.parser')
data = soup.find_all('tbody')
5. Inzwischen hat jeder Benutzer den “tbody” gespeichert, indem er die find_all()-Methode verwendet hat, die ebenfalls von der beautifulsoup-Bibliothek bereitgestellt wird.
Die Sache ist die, dass sich die erforderlichen Daten in zwei verschiedenen Tabellen befinden und der Benutzer daher die erforderlichen Daten mit denselben Codezeilen abrufen muss, aber die Variable, die dieses Mal verwendet werden soll, ist eine andere, wie unten gezeigt:
# getting tables from the content
try:
table = data[0].find_all('tr')
except:
table = None
try:
table_1 = data[1].find_all('tr')
except:
table_1 = None
6. Im nächsten Schritt werden die Daten aus den auf der Website vorhandenen Tabellendaten extrahiert und gespeichert, und zu diesem Zweck werden viele Wörterbücher erstellt.
In unserem Beispiel des erstellten Wörterbuchs wird keys der Name sein, der den gespeicherten Werten gegeben wird, und auch values ist derjenige, der die tatsächlichen und wahren Werte enthält.
Dies ist, wie es unten mit nur einem einfachen Code, der leicht zu verstehen ist getan werden kann:
# declare empty dictionary
final_dict = dict()
for i in range(0,len(table)):
try:
table_name = table[i].find_all('td')
except:
table_name = None
final_dict[table_name[0].text] = table_name[1].text
for i in range(len(table_1)):
try:
table_name = table_1[i].find_all('td')
except:
table_name = None
final_dict[table_name[0].text] = table_name[1].text
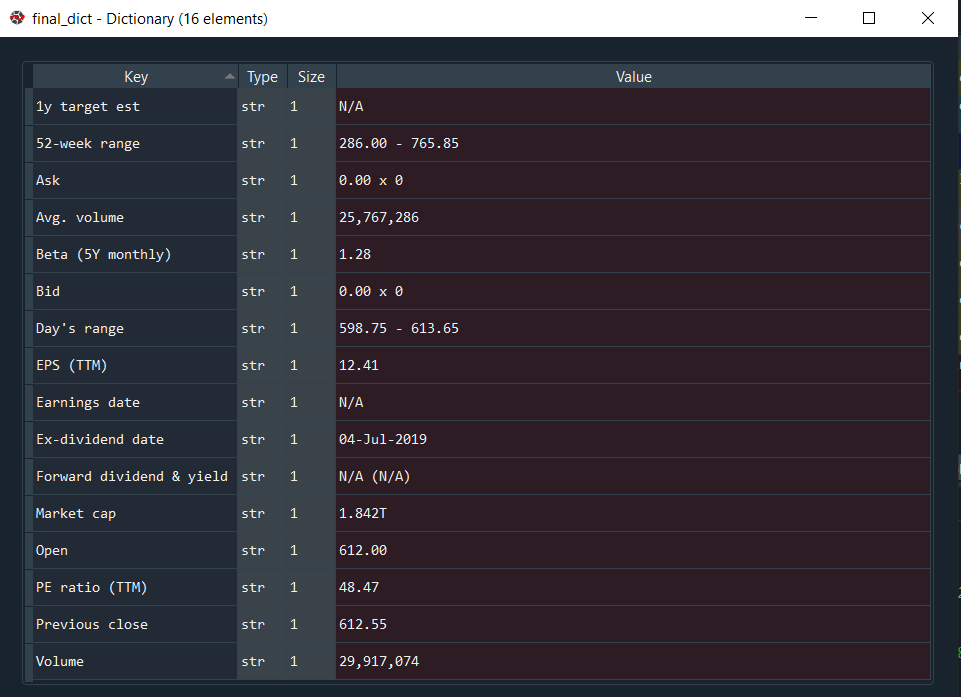
7. Und außerdem wird das Ergebnis in etwa so aussehen:
Nach unserem Verständnis :
Mit diesem Leitfaden wird es einfach für jeden Benutzer, um jeden Prozess der Schaben von Informationen von jeder Website einschließlich Yahoo Finance, voll automatisiert ohne viel Störung und Ärger und minimale Zeile von Codes zu bekommen.
Wir von de.scrapingpass.com haben Ihnen zu Lehrzwecken die Mittel und Wege aufgezeigt, wie Sie auf einfache und für jeden verständliche Art und Weise beliebige Informationen von Yahoo Finance abgreifen können. Weitere Tools können Sie hier nachlesen.
Indem wir den gesamten Prozess so effizient wie möglich beschreiben, haben wir Ihnen gezeigt, wie Sie mit unserer Methodik und unseren Tools Daten aus Yahoo Finance scrapen können.
Vivek
More posts by Vivek