

Scraping ist eine gängige Praxis in der aktuellen Programmier- und schnelllebigen Technologie-Ära. Viele von uns haben Scraping für unsere üblichen täglichen Programmieraufgaben verwendet.
Aber sind Sie schon einmal auf einen Fall gestoßen, in dem Sie Requests oder wget für den Zugriff auf eine beliebige Webseite verwenden und einen völlig anderen HTML-Inhalt erhalten?
Ja, Sie sind nicht der einzige, der mit diesem Problem konfrontiert ist. Einige Entwickler sind klug genug, um ihre wertvollen Daten vor solchen Crawlern oder Scrapern zu schützen.
Aber haben Sie sich schon gefragt, wie man geschickt zwischen einer normalen Browser-Anfrage und einer automatisierten Python-Anfrage unterscheiden kann?
In diesem Blog werden wir uns ansehen, wie dies grundsätzlich geschieht und wie wir eine intelligente und dennoch einfache Lösung für ein solches Problem schreiben können, indem wir nur ein paar Zeilen Code in Ihrer Lieblings-Programmiersprache “Python” verwenden.
In diesem Blog werden wir jeden Aspekt des User-Agents behandeln. Dieser Blog ist in mehrere Teile gegliedert:
- Was ist ein User-Agent?
- Aufschlüsselung eines User-Agents
- Warum brauchen wir einen User-Agent?
- Schritte beim Drehen eines User-Agents
Was ist ein Benutzer-Agent?
Ein User Agent ist nichts anderes als ein einfacher Satz von Zeichenfolgen, die jede Anwendung oder jeder Browser sendet, um auf die Webseite zuzugreifen.
Nun stellt sich die Frage, was im Grunde genommen diese Strings sind, die dem Server helfen, zwischen einem Browser und einem Python-Skript zu unterscheiden.
Die Bestandteile eines typischen User-Agents sind wie folgt
- das Betriebssystem
- der Anwendungstyp
- die Software-Version bzw.
- der Softwarehersteller der anfragenden Software User-Agent.
Nun stellt sich die Frage: “Warum werden Informationen wie Betriebssystem und Softwareversionen benötigt?”
Nun, die Antwort ist ganz einfach, um die Webseite entsprechend Ihrer Hardware und Software zu optimieren.
Schauen wir uns ein Beispiel für den User-Agent an. Wir werden uns den Lieblingsbrowser eines Open-Source-Entwicklers ansehen, Mozilla Firefox.
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTM, like Gecko) Chrome/51.0.2704.103 Safari/537.36
Aufschlüsselung eines User-Agenten
Hier im obigen Beispiel sind alle Details, über die wir zuvor in diesem Artikel gesprochen haben. Lassen Sie uns nun aufschlüsseln und sehen, welcher Teil damit verbunden ist.
<browser>/<version> - Mozilla/5.0 (<system information>) - (X11; Linux x86_64) <platform> - AppleWebKit/537.36 (<platform-details>) - (KHTM, like Gecko) <extensions> - Chrome/51.0.2704.103 Safari/537.36
Schauen wir uns nun an, wie sich eine normale Webseiten-Anfrage mit Standard-Python-Bibliotheken wie ‘requests’ & ‘wget’ von einer Browser-Anfrage unterscheidet. Wir werden für dieses Beispiel ‘requests’ betrachten.
import requests
from pprint import pprint
# using HTTPBin to get the header for our requests
r = requests.get('http://httpbin.org/headers')
pprint(r.json())

Beispiel für einen Benutzer-Agenten
Warum brauchen wir einen User Agent?
Wie wir nun in der Antwort selbst sehen können, ist der User Agent ‘python-requests/2.24.0’. So kann ein Server also den Unterschied zwischen einer normalen Browser-Anfrage und python requests() erkennen. Nun wollen wir sehen, wie wir diesen User-Agent ändern und durch einen Browser User-Agent mit Python ersetzen können.
Nun, wenn Sie beobachtet haben, hat die Antwort, die wir erhalten haben, ein Wörterbuch und der Schlüssel dazu ist ‘headers’. Nun müssen wir unseren User-Agent auf die Python-Anfragen abbilden.
Für unser Beispiel werden wir den User-Agent aus dem obigen Beispiel mit requests.
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTM, like Gecko) Chrome/51.0.2704.103 Safari/537.36 '}
r = requests.get('http://httpbin.org/headers', headers=headers)
pprint(r.json())

Dummy-Benutzer-Agent
Wenn Sie den obigen Code verwenden, erhalten Sie eine Ausgabe, die einer Browser-Anfrage “User-Agent” ähnelt, wie in der Abbildung unten zu sehen ist, aber es ist nicht genau so, da noch einige Komponenten fehlen.
Lassen Sie uns einen Blick auf eine tatsächliche Browser-Anfrage werfen.
{
"headers": {
"Accept": "text/html.application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng*/*;q=0.8,application/signed-exchage;v=b3'q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": 'en-GB,en-US;q=0.9,en;q=0.9",
"Dnt": "1",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"user-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTM, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
"X-Amzn-Track-Id": "Root=1-5ee7bae0-82260c065baf5d7f0533e5"
}
}
Da wir nun einige weitere Dinge gefunden haben, die in unserem Header hinzugefügt werden müssen, um unseren User-Agent und Header narrensicher zu machen, wie Accept-Language, Dnt, Upgrade-Insecure-Requests.
Wir sollten also den Header ein wenig mehr bearbeiten.
headers = {
"Accept": "text/html.application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng*/*;q=0.8,application/signed-exchage;v=b3'q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": 'en-GB,en-US;q=0.9,en;q=0.9",
"Dnt": "1",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"user-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTM, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
}
r = requests.get('http://httpbin.org/headers', headers=headers)
pprint(r.json())
Wie wir in der unten stehenden Antwort sehen können, ist die Ausgabe die gleiche wie die eines Browsers.
Ein Seufzer der Erleichterung, jetzt können Sie ganz einfach mit dem Scraping beginnen, ohne sich Sorgen machen zu müssen, dass Ihre IP-Adresse richtig blockiert wird!
Nun, es ist noch nicht ganz geschafft, Sie sind auf halbem Wege.
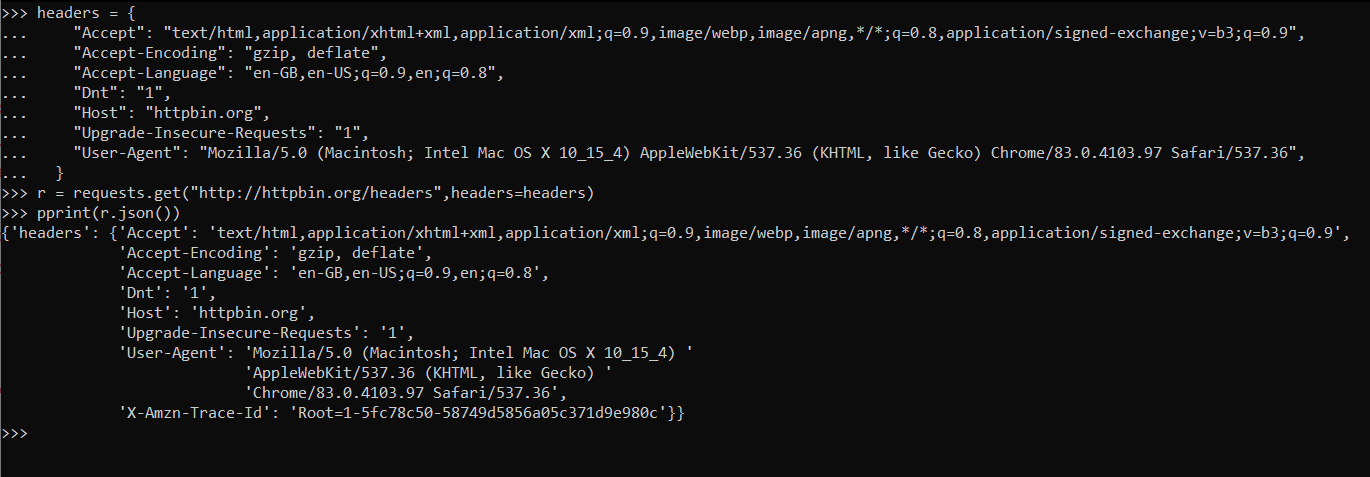
Browser-Benutzer-Agent-Beispiel
Es gibt einige Dinge, um die man sich kümmern muss, bevor man sich entspannt zurücklehnen kann, und das ist die User-Agent-Rotation.
Es ist nichts anderes als ein Satz von gerade oben erklärten Headern, so dass es zufällig einen davon auswählen und fortfahren kann, ohne dass Anfragen mit demselben Header gestellt und blockiert werden.
Schritte zum Drehen von Benutzer-Agenten
Wenn Ihr Ziel nur das Rotieren von Benutzer-Agenten ist, lassen Sie uns nun besprechen, wie wir dies anhand der folgenden Schritte implementieren können. Der Prozess ist sehr einfach.
- Sie können eine Liste der aktuellen Browser User-Agent sammeln, indem Sie die folgende Webseite WhatIsMyBrowser.com aufrufen.
- Speichern Sie sie in einer Python-Liste.
- Schreiben Sie eine Schleife, um einen zufälligen User-Agent aus der Liste für Ihren Zweck auszuwählen.
import requests
import random
user_agent_list = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
]
url = 'https://httpbin.org/headers'
for i in range(1,4):
# Pick a random user agent
user_agent = random.choice(user_agent_list)
# Set the headers
headers = {'User-Agent': user_agent}
# Make the request
response = requests.get(url,headers=headers)
print("Request #%d\nUser-Agent Sent:%s\n\nHeaders Recevied by HTTPBin:"%(i,user_agent))
print(response.json())
print("-------------------")
Das ist alles, was Sie tun müssen, um die User-Agent-Rotation mit Python zu implementieren. Nachfolgend sehen Sie die Ausgabe des obigen Codes.
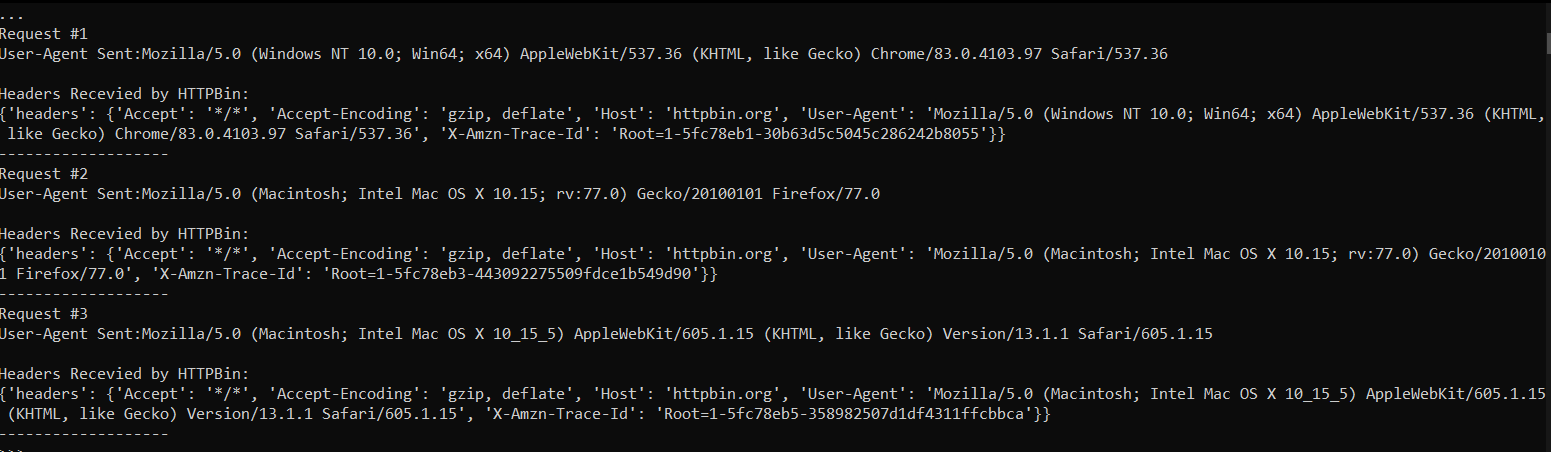
Endgültige Ausgabe für User-Agent-Rotation
Herzlichen Glückwunsch, Sie haben erfolgreich den User-Agent für ein nahtloses Scraping gedreht, aber einige Websites haben einen strengen Anti-Scraping-Mechanismus, der schließlich auch dieses Muster erkennen kann.
Obwohl dieser Prozess verwendet werden kann, ist er viel mühsamer als Sie sich vorstellen können. Was wir vorschlagen, ist die Verwendung einiger Tools für eine mühelose Erfahrung.
ScrapingPass ist einer der besten Scraping-Dienstleister, die heute verfügbar sind und eine Reihe von verschiedenen Dienstleistungen zu extrem günstigen Preisen anbieten.



Vivek
More posts by Vivek