

Im aktuellen Wettbewerbsszenario verlagert sich das Einkaufen auf eine mühelose und umfassende Produktvarianten-Umgebung, die E-Commerce ist. Wenn Sie ein E-Commerce-Geschäft betreiben, haben Sie vielleicht das Gefühl, dass Sie eine Art von Amazon Data Scraper benötigen, mit dem Sie sich von der Konkurrenz abheben können. Da der E-Commerce boomt und der Wettbewerb exponentiell zunimmt, kann man sich einen Vorteil verschaffen, wenn man die Technologie auf die richtige Art und Weise nutzen kann, um Einblicke zu erhalten und den Markt für eine bessere Produkt-Markt-Anpassung zu analysieren. Wir können Informationen von der E-Commerce-Website abrufen, um Informationen wie Produktpreise und Bewertungen zu erhalten.
In diesem Blog werden wir besprechen, wie wir Produktpreise und Bewertungslinks von Amazon abgreifen können. Dies ist ausschließlich für Bildungszwecke und wir empfehlen Ihnen, die FAQ von Web Scraping zu überprüfen, bevor Sie diesen Artikel lesen. Dazu werden wir Python und einige Open-Source-Bibliotheken wie Requests und SelectorLib für unsere Zwecke verwenden.
Zu installierende Pakete für Amazon Data Scraper
-
Requests
Es ist ein Open-Source-Python-Paket, das verwendet wird, um HTTP-Anfragen zu stellen und den Inhalt der Seite herunterzuladen, die in unserem Fall die Amazon-Produktseite ist.
-
SelectorLib
Es handelt sich um ein Python-Paket, das prompt zum Extrahieren von Daten über die YAML-Datei verwendet wird.
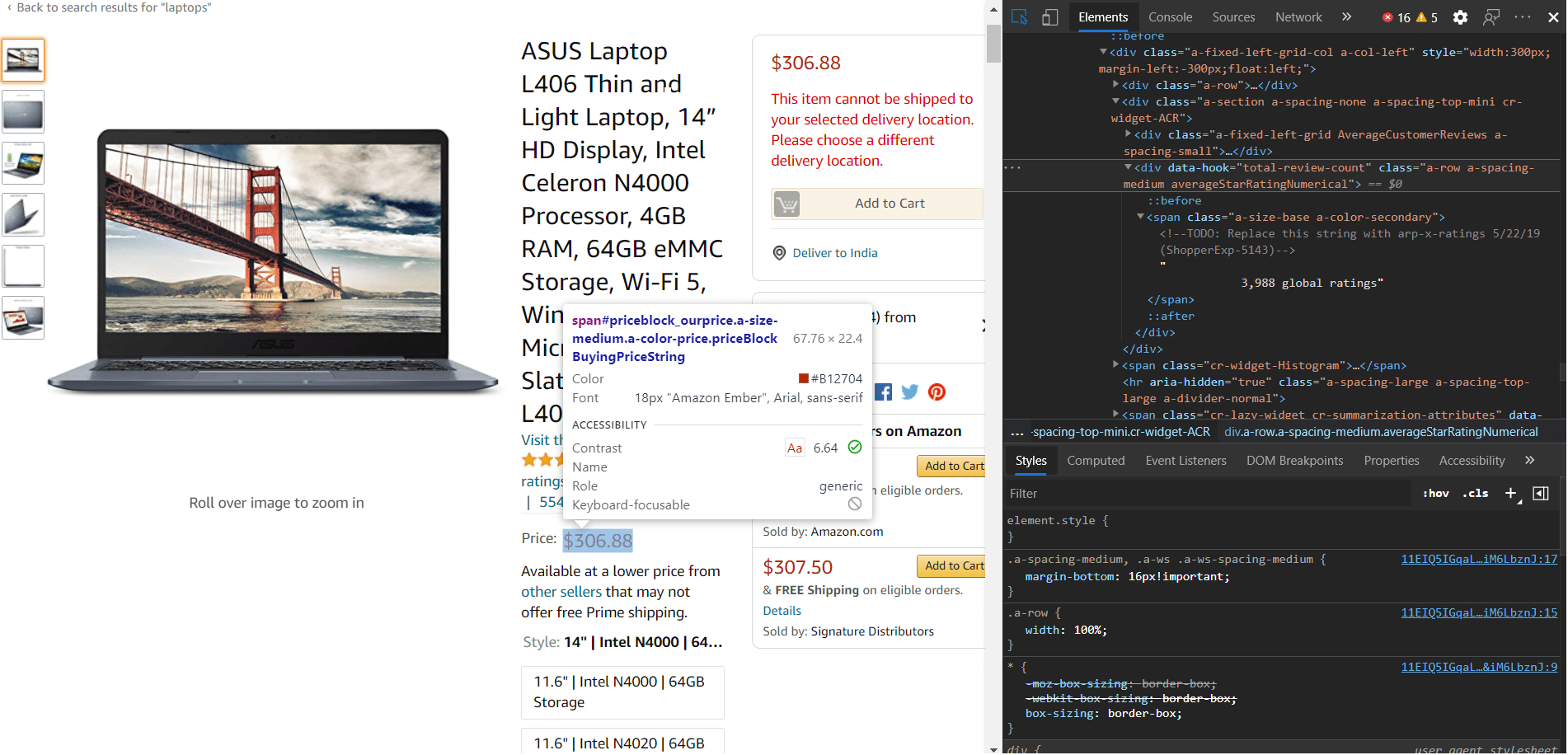
Für diese Aufgabe werden wir uns darauf konzentrieren, die folgenden Details von der jeweiligen Produktseite zu extrahieren.
- Name
- Preis
- Produkt-Bilder
- Beschreibung des Produkts
- Link zu Bewertungen
4 Schritte zum Erstellen von Amazon Data Scraper mit Python
-
Beginnen wir mit der HTML-Struktur in der Datei Selector.yml
Wir sollten zunächst damit beginnen, eine selector.yml-Datei zu erstellen, die alle unsere CSS-Tags und HTML-Strukturtypen und Attribute enthalten wird. Dazu müssen wir Bereiche mithilfe von “inspect element” oder “developer tools” in einem beliebigen Browser auswählen. Nach sorgfältiger Auswahl eines Attributs können Sie alle Informationen in der Datei selector.yml speichern. Als Referenz haben wir den Code für die Tags unten hinzugefügt.
name: css: '#productTitle' type: Text price: css: '#price_inside_buybox' type: Text images: css: '.imgTagWrapper img' type: Attribute attribute: data-a-dynamic-image rating: css: span.a-icon-alt type: Text product_description: css: '#productDescription' type: Text link_to_all_reviews: css: 'div.card-padding a.a-link-emphasis' type: Link -
Erstellen Sie eine url.txt-Datei, um Links für die Elemente hinzuzufügen
Da wir nun mit den Tags fertig sind, können wir nun alle Links für die Seiten in eine urls.txt-Datei eintragen. Bei genauer Betrachtung haben wir festgestellt, dass die HTML-Struktur für alle Seiten gleich ist. Unten sehen Sie die urls.txt-Datei.
https://www.amazon.com/ASUS-Display-Processor-Microsoft-L406MA-WH02/dp/B0892WCGZM/ https://www.amazon.com/HP-15-Computer-Touchscreen-Dual-Core/dp/B0863N5FM8/
-
Beginnen Sie mit dem Haupt-Python-Skript, um diese Dateien zu verwenden
Da wir nun mit allen Grundvoraussetzungen fertig sind, sollten wir uns nun auf das Python-Skript konzentrieren, das diese beiden Dateien ausführen wird. Stellen Sie vorher sicher, dass alle Abhängigkeiten erfüllt sind. Wir werden Requests verwenden, um Daten von der Webseite zu erhalten. Für die Verwendung der Datei selector.yml benötigen wir die Bibliothek selectorlib und ihre Extractor-Funktion, die als Header in requests.get() übergeben werden kann.
from selectorlib import Extractor import requests import json # Create an Extractor by reading from the YAML file e = Extractor.from_yaml_file('selectors.yml') def scrape(url): headers = { 'authority': 'www.amazon.com', 'pragma': 'no-cache', 'cache-control': 'no-cache', 'dnt': '1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp, image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'sec-fetch-site': 'none', 'sec-fetch-mode': 'navigate', 'sec-fetch-dest': 'document', 'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8', } # Download the page using requests print("Downloading %s"%url) r = requests.get(url, headers=headers) # Simple check to check if page was blocked (Usually 503) if r.status_code > 500: if "To discuss automated access to Amazon data please contact" in r.text: print("Page %s was blocked by Amazon. Please try using better proxies\n"%url) else: print("Page %s must have been blocked by Amazon as the status code was %d"% (url,r.status_code)) return None # Pass the HTML of the page and create return e.extract(r.text) with open("urls.txt",'r') as urllist, open('output.json','w') as outfile: for url in urllist.readlines(): data = scrape(url) print(data) if data: print(data) json.dump(data,outfile) outfile.write("\n") -
Erzeugen der Datei output.json als Ergebnis
Jetzt verwenden wir Anfragen, um den HTML-Inhalt zu erhalten und mit dem definierten Inhalt im ‘header’-Wörterbuch und wenn wir den Inhalt haben, werden wir alle Tags mit der Funktion extractor() extrahieren. und das Wörterbuch zurückgeben. Nach der Rückgabe werden wir dies in eine ‘output.json’-Datei schreiben.
So können Sie also die Amazon-Produktseite mit diesem Amazon Data Scraper scrapen, um Ihr Produkt zu verbessern und Einblicke zu erhalten, sei es die Kundenstimmung oder die Preisgestaltung der Wettbewerber. Es gibt auch andere mögliche Wege, die für Ihren Fall nützlich sein können, aber wenn wir Scraping verwenden, gibt es eine Menge Dinge hinter den Kulissen, die wir berücksichtigen müssen, wie Proxy-Service, User-Agent-Rotation, Captcha-Auflösung, etc. An dieser Stelle kommt ScrapingPass ins Spiel. Wir kümmern uns um all diese Hindernisse, damit Sie sich auf die Verbesserung Ihres Produkts konzentrieren können, während Sie unsere Dienste nutzen.



Vivek
More posts by Vivek