

Es gibt zu viele Daten in der modernen Internet-Einrichtung zu handhaben. Damit einher geht das Konzept von Websites, die eine große Menge an Daten über verschiedene Dinge in der Welt enthalten.
Während Websites eine große Menge an Daten tragen, ist es schwer, die Daten zu finden, die für einen bestimmten Benutzer relevant sind. An dieser Stelle kommen das Konzept des Web Scraping und de.Scrapingpass.com ins Spiel.
Es ist der Akt des Extrahierens der benötigten und relevanten Daten von jeder Website, die ein Benutzer braucht, und wir sind ausgezeichnet darin. Wir haben alles, was ein Entwickler braucht, um Website-Informationen zu scrapen.
Unsere Methodik und Tools basieren auf einer schnellen und effizienten Extraktion von Informationen und unterstützen mehrere Sprachen für die Benutzerfreundlichkeit.
Im Folgenden werden wir die besten 7 JavaScript Web Scraping Bibliotheken für den Akt des Web Scraping besprechen und Sie können auch die 10 besten kostenlosen Web Scraping Tools überprüfen.
Außerdem können Sie hier mehr über Scraping erfahren.
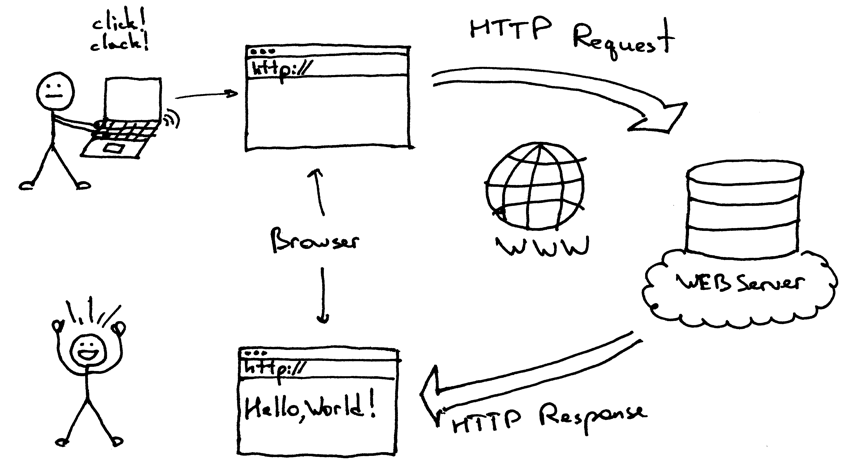
Top JavaScript Web Scraping Bibliotheken :
1. Request :
Für die schnelle Implementierung von HTTP- und JavaScript-Web-Scraping ist dies eine der am häufigsten verwendeten und einfachsten Bibliotheken, die in JavaScript vorhanden sind.
- Sie ist recht einfach zu implementieren und zu verstehen und hat eine unkomplizierte Art, sie zu benutzen. Daher kann man sie leicht und ohne Schwierigkeiten für Komplexitäten verwenden.
- Es hat auch einen Vorteil, weil es HTTP5 unterstützt, die standardmäßig gerichtet sind.

Das Auslesen von Inhalten aus einer Seite mit Requests ist so einfach wie die Übergabe einer URL, wie im folgenden Beispiel gezeigt,
const request = require('request');
request('http://scrapingpass.com', function(er, res, bod) {
console.error('error: ',er) // print error
console.log('body: ',bod); //print request body
});
Dies sind die am häufigsten verwendeten und am häufigsten vorkommenden Anweisungen, die in der Implementierung der Bibliothek vorhanden sind.
URL oder Uniform Resource Locator:
Es ist die Ziel-URL der HTTP-Anfrage des Benutzers
Methode:
Eine der HTTP-Methoden wie GET, DELETE, POST, die verwendet werden soll.
Header:
Dies ist ein Objekt, das verwendet werden wird und HTTP-Header (Schlüssel-Wert) darstellt
Form:
Der Schlüsselwert aus den vorhandenen Daten ist in diesem Objekt enthalten.
Was sind die Vorteile der Verwendung von Requests?
Hier sind die Vorteile der Verwendung :
- Authentifizierung von HTTP
- Unterstützung in Form eines Proxys
- Ein Protokoll, das TLS/SSL unterstützt
- Callback- und Streaming-Schnittstellen werden unterstützt
- Der beste Teil ist, dass die meisten HTTP-Methoden unterstützt werden, wie GET, POST, etc.
- Formular-Uploads werden unterstützt.
- Man kann die Verwendung von benutzerdefinierten Headern implementieren.
2. Cheerio :
Eine der berühmten JavaScript-Web-Scraping-Bibliotheken trägt den Namen Cheerio.
Sie ist berühmt, weil sie Entwicklern und Anwendern die Freiheit gibt, sich auf die heruntergeladenen Daten zu konzentrieren und nicht auf das Parsen der Daten.
Eine weitere großartige Tatsache über Cheerio ist, dass es sehr flexibel und zuverlässig ist und dazu noch schnell, was eine großartige Kombination ist.
Es verfügt über die gleiche Teilmenge des jQuery-Kerns und daher kann der Benutzer die jQuery- und Cheerio-Umgebung bei der Implementierung von JavaScript-Web-Scraping austauschen, was es insgesamt schnell macht.
Das Starten mit Cheerio ist ganz einfach und hier ist, wie man es macht:
var cheer = require('cheerio');
$ = cheeri.load('<h1 id="heading">Hi Folks</h1>');
Damit kann der Anwender das $ wie gewohnt in jQuery verwenden
$('#heading').text("Hello Geeks");
console.log($.html()); // return html example : <h1 id="heading">Hello Geeks</h1>
Am Ende muss der Benutzer die Paketanforderung in npm install request durchführen. Hier erfahren Sie, wie Sie www.google.co.in HTML-Inhalte auf effiziente und einfache Weise in Ihre Shell bekommen.
var request = require('request');
var cheerio = require('cheerio');
request('http://www.google.com/', function(err, resp, body) {
if (err)
throw err;
$ = cheerio.load(body);
console.log($.html());
});
Was sind die Vorteile der Verwendung von Cheerio?
Lassen Sie uns über die Vorteile sprechen:
- Da Cheerio eine Untermenge von jQuery ist, gibt es viele Ähnlichkeiten in der Syntax.
- Die Beseitigung von DOM-Konsistenzen bewirkt, dass der Benutzer die brillante API sieht.
- Im Prozess des Parsens, der Manipulation und des Renderns der Eingabedaten ist Cheerio ziemlich schnell und auch zuverlässig.
- Das Beste daran ist, dass Cheerio in der Lage ist, jede Art von HTML- oder XTL-Datei zu parsen, was für die Benutzer einfach großartig ist.
3. Osmosis :
Osmosis gilt als eine der effizientesten und hochwertigsten Javascript-Web-Scraping-Bibliotheken.
- Mit Osmosis können komplexe Seiten ohne Kenntnisse und Verwendung von viel Kodierung gescraped werden, was für die meisten Benutzer einfach großartig ist.
- Osmosis scrabbt und parst XML und HTML und ist in node.js implementiert, zusammen mit css3/XPath-Selektor gepackt, und es gibt auch einen leichtgewichtigen HTTP-Wrapper.
- Eine weitere Sache ist, dass Osmosis im Gegensatz zu Cheerio keine riesigen Abhängigkeiten hat, und das ist ziemlich gut.
![]()
To begin with, we can see below how using Osmosis, one can scrape a Wikipedia page which consists of a list of the popular Hindu festivals that are celebrated across India.
osmosis
.get('https://en.wikipedia.org/wiki/List_of_Hindu_festivals')
.set({ mainHeading: 'h1',
title: 'title'
})
data(list => console.log(list));
Hier ist das Ergebnis :
{ mainHeading: 'List of Hindu festivals',
title: 'List of Hindu festivals - Wikipedia' }
Lassen Sie uns über den Fall sprechen, in dem der Benutzer alle Festivals finden möchte.
Diese Daten werden, wie gesehen, in der nächsten Tabelle auf der gleichen Seite verfügbar sein. Daher wird der Benutzer eine weitere Funktion namens “find” implementieren.
Diese wird bei der Auswahl des aktuellen Kontextes mit der Verwendung des Selektors nützlich sein. Danach weisen wir Osmosis an, die Daten aus der ersten Zeile zu sammeln, und am Ende werden wir die gewünschten Ergebnisse erzielen.
osmosis
.get(url)
.set({ title: 'title' })
.find('.wikitable:nth-child(2) tr:gt(0)')
.set({festival:'td[0]'})
.data(list => console.log(list));
Schauen wir uns das Ergebnis an:
{ festival: 'Bhogi'}
{ festival: 'Lohri',}
{ festival: 'Vasant Panchami'}
...
Was sind die Vorteile der Osmosis?
Hier sind ein paar der vielen Vorteile, die Osmosis hat:
- Selektor-Hybride wie die CSS 3.0 zusammen mit XPath 1.0 werden sehr gut unterstützt.
- Proxy-Ausfall wird leicht behandelt
- Redirects und auch Wiederholungen der Limits.
4. Puppeteer :
Eine der großen und effizienten Javascript-Web-Scraping-Bibliotheken, die von der berühmten und vertrauenswürdigen Google Chrome im Jahr 2018 entworfen wurden, führte viel besser als die Leistungen von anderen großen Lösungen wie die Phantom JS oder Selenium, wenn in der Beziehung mit Geschwindigkeit und Effizienz verglichen.
Das ist einfach erstaunlich.
Ein weiterer großartiger Teil ist, dass es ziemlich stabil ist und auch, kann leicht in Googles Chome oder Chromium-Browser behandelt werden.
Die großartigen Eigenschaften dieses Programms sind:
- Verschiedene Formular-Eingaben können effizient automatisiert werden.
- Screenshots können bei Bedarf einfach erstellt werden
- Automatisierungstests können erstellt werden
- Erstellung von PDFs aus Webseiten im Internet
So installieren Sie den Puppeteer in das Anwenderprojekt und führen ihn anschließend aus :
npm install puppeteer
Damit findet ein Download der neuesten Chromium-Version statt.
Man kann auch den Puppeteer-Kern verwenden, wenn man diesen auf dem lokalen Chrome-Browser selbst ausführen möchte.
Was sind die Vorteile der Verwendung von Puppeteer?
Schauen wir uns einige Vorteile von Puppeteer an:
- Zeigen-und-Klicken-Schnittstelle.
- Timeline-Trace, wenn der Benutzer irgendwelche Fehler herausfinden möchte.
- Damit kann der Benutzer Screenshots machen.
- Webseiten im Internet können in PDF-Dateien erstellt werden

5. Playwright
Der Playwright ist eine weitere der guten und zuverlässigen offenen JavaScript-Web-Scraping-Bibliotheken, die von demselben Team entwickelt wurden, das auch Puppeteer entworfen hat, sich aber seitdem weiterentwickelt hat.
- Sie ist so konzipiert, dass sie Firefox-Chromium und auch Web Kit mit der Implementierung einer einzigen API automatisieren kann.
- Das Ziel ist es, eine Alternative zu WebDriver zu sein, der ein Riese auf dem Gebiet der W3C-Web-Automatisierung ist.
Wenn Sie es installieren möchten, finden Sie hier die Anleitung dazu:
npm i playwright
API ist recht ähnlich, wie unten zu sehen:
(async () => {
for (const browserType of ['chromium', 'firefox', 'webkit']) {
const browser = await playwright[browserType].launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('http://whatsmyuseragent.org/');
await page.screenshot({ path: `example-${browserType}.png` });
await browser.close();
}
})();
Was sind die Vorteile der Verwendung von Playwright?
Hier sind einige der vielen Vorteile :
- Die Eingaben von nativen Mäusen und Tastaturen sind möglich
- Es ist einfach, die Benutzerdateien sowohl hoch- als auch herunterzuladen.
- Es gibt Szenarien, die sich über mehrere Seiten und Iframes erstrecken.
- Emulation von Berechtigungen und mobilen Geräten
6. Axios
Axios kann leicht in der Implementierung des Frontends und auch im node. js bezogenen Backend verwendet werden und sticht aus den vielen Javascript-Web-Scraping-Bibliotheken heraus.
- Asynchrone HTTP-Anfragen werden sehr einfach an ihren REST-Punkt am Ende gesendet.
- Auch die Durchführung von CRUD-Operationen ist sehr einfach und ihre Implementierung wird sehr einfach, da Axios ein sehr einfaches Paket hat, das es daher den Benutzern ermöglicht, die Webseiten von verschiedenen anderen Orten aus aufzurufen.
- Die Axios-Bibliothek kann in einfachen Javascript-Anwendungen oder in Zusammenarbeit mit komplexeren Vue.js verwendet werden.
Lassen Sie uns ein Szenario nehmen,
const axios = require('axios');
// Make a request for a client with a given token
axios.get('/client?token=12345')
.then(function (resp) {
// print response
console.log(resp);
})
.catch(function (err) {
// print error
console.log(err);
})
.then(function () {
// next execution
});
Dann installieren Sie Axios :
npm i axios
So kann bower verwendet werden:
bower install axios
oder sogar yarn :
yarn add axios
Was sind die Vorteile der Verwendung von Axios?
Für diejenigen, die es kennen, ist es recht vorteilhaft :
- Requests können leicht abgebrochen werden
- CSRF-Schutz ist bereits eingebaut
- Upload-Fortschritt wird unterstützt
- JSON-Datenumwandlung ist ein automatischer Prozess
7. Unirest
Eine ziemlich berühmte Bibliothek für Javascript Web Scraping. Ruby, .Net, Python, und auch, Java sind alle in dieser Bibliothek unterstützt.
Hier sehen Sie, wie Unirest installiert wird:
$ npm i unirest
Vereinfachen Sie Anfragen wie angegeben:
var unirest = require('unirest');
Was sind die Vorteile von Unirest?
Also, das sind die Vorteile :
- Die meisten HTTPS-Methoden wie DELETE, etc. werden unterstützt
- Uploads von Formularen werden unterstützt, falls Benutzer sie benötigen
- Autentifizierung von HTTP ist auch vorhanden
Was sagt das Urteil?
Dies waren einige der besten Scraping-Tools, die es gibt. Aber das von uns verwendete ist de.ScrapingPass, das in jeder Hinsicht exzellent ist, zusammen mit großartigen Dienstleistungen.
Die Verwendung von Anfragen kann sowohl, einfach und freundlich, stehen auf der Liste aus. Es gibt mehrere Ströme dieses Flusses und mit solchen großen Dienstleistungen, es übertrifft die meisten der Javascript Web Scraping Bibliotheken auf der Liste.
Aber im Allgemeinen haben alle diese Bibliotheken brillant gearbeitet und unzähligen Benutzern gedient. Letztendlich hängt alles von der Überlegung und Entscheidung des Anwenders ab, die er nach Prüfung seines Ziels und der benötigten Funktionen treffen sollte.
Es ist also der Benutzer, der das Beste aus all den Javascript-Web-Scraping-Bibliotheken wählen muss.



Vivek
More posts by Vivek