

Wenn man von Daten spricht, geht es nicht nur um tabellarische oder textuelle Daten. Durch die Weiterentwicklung der Technologien sind wir heute in der Lage, riesige Bilder, Videos und Audiodaten in einem Bruchteil der Zeit zu verarbeiten. Mit dem Fortschritt und der schnell wachsenden Technologie haben wir zahlreiche Anwendungen von Daten. Wir benötigen riesige Daten, um eine Lösung auf Basis von Merkmalen in Bildern zu entwickeln, Informationen aus ihnen zu extrahieren oder Schlussfolgerungen aus ihnen zu ziehen.
Es ist ein bekanntes Sprichwort beim maschinellen Lernen: “Ein maschinelles Lernmodell kann seine Trainingsdaten nicht übertreffen. Daher ist es für Sie sehr wichtig, die bestmögliche Bilddatenerfassung für Ihr maschinelles Lernmodell zu erhalten, um ein überlegenes maschinelles Lernmodell zu erhalten.
In unserem heutigen Beispiel werden wir zeigen, wie man einen Scrapper aus einer statischen Webseite entwickelt. Für unser Beispiel werden wir eine Website für Yoga-Haltungen scrappen. Wir werden Bilder, die auf “https://greatist.com/” verfügbar sind, scrappen und sie mit urllib speichern.
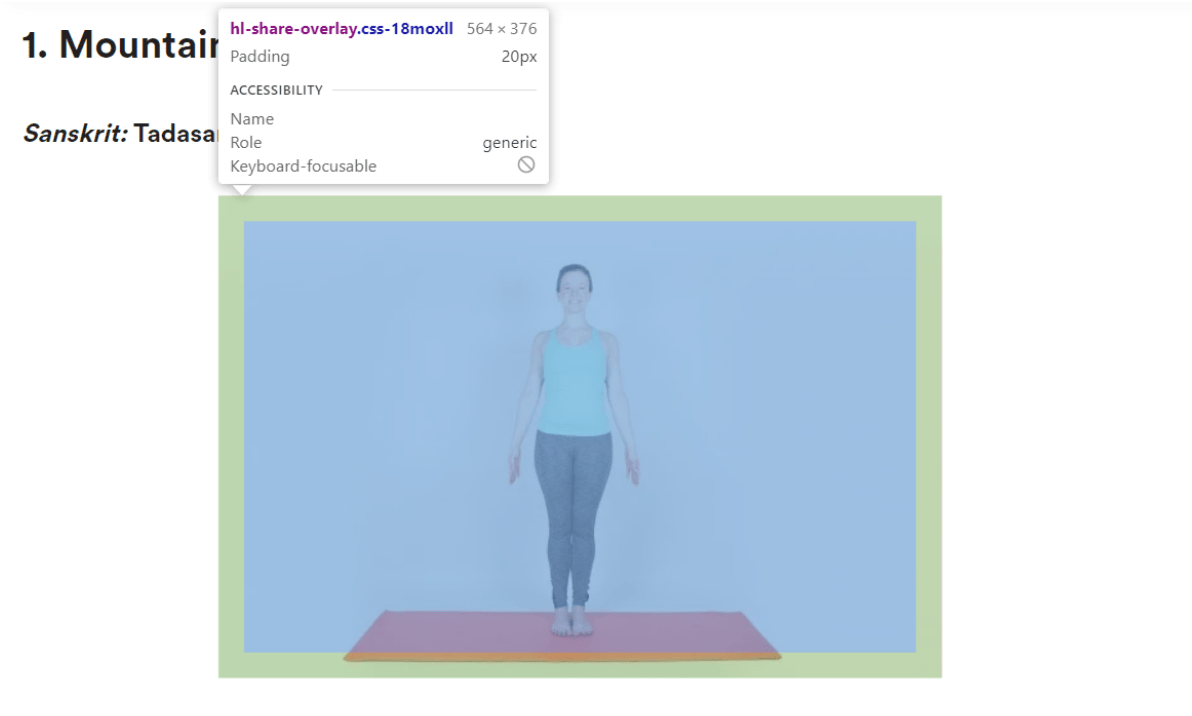
Yoga-Haltung
Wir sollten damit beginnen, den Inhalt der Webseite zu erhalten. Hierfür benötigen wir die requests-Bibliothek. Wir speichern die URL in einem Container namens ‘url’ und übergeben diesen an die Funktion requests.get(). Nachdem wir die Antwort erhalten haben, parsen wir die Webseite mit BeautifulSoup und konvertieren sie mit dem unten stehenden Code in eine HTML-Baumstruktur.
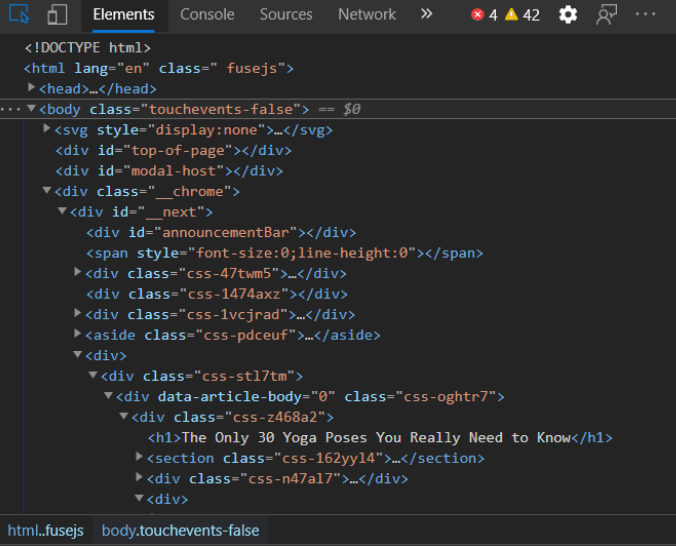
Beispiel-Code
import requests from bs4 import BeautifulSoup url = 'https://greatist.com/move/common-yoga-poses#easy' req = requests.get(url) soup = BeautifulSoup(req.content, 'html.parser')
Jetzt müssen wir mit BeautifulSoup nach dem Tag suchen, um die Bilder von der Seite zu bekommen. Wir müssen durch die Bilder gehen, um jeden Quell-Link zu bekommen und können sie dann im .jpg-Format speichern. wir müssen nach dem Bild-Tag und dann nach der Quelle suchen. In der Quelle finden wir den Link und können ihn bereinigen, um die tatsächliche URL des Bildes zu erhalten, indem wir unterhalb der Schleife verwenden.
for picture in soup.find_all('picture',class_='css-16pk1is'):
link = 'http:' + picture.find('source')['srcset'].split('?')[0]
name = link.split('/')[-1]
urlretrieve(link,name)
Jetzt verwenden wir urlretrieve() aus der Bibliothek urllib.request, um es in einem .jpg-Format zu speichern. Diese Funktion nimmt die URL als Eingabe und den Namen der zu speichernden Datei auf.



Vivek
More posts by Vivek