

Web Scraping in einem Machine Learning Modell :
Die Datenanalyse ist ein langwieriger Prozess, der als Teil davon eine Vorverarbeitung der Daten erfordert. Im Fall von maschinellem Lernen und anderen statistischen Theorien und Projekten ist es erforderlich, dass die wertvollen Daten behalten und die Mülldaten weggeworfen werden.
Die Sache ist die, dass die Datenerfassungstechniken oft locker gestrickt sind und dies führt zu bestimmten ungenauen Daten oder inkonsistenten Datensätzen oder vielen Werten außerhalb des Bereichs von Müll.
Es ist notwendig, solche Daten zu eliminieren, da sie die Nutzung der Daten behindern und dies kann mit Hilfe von Web Scraping geschehen und hier kommen wir ins Spiel.
Wir, bei Scrapingpass.com, sind da, um alle Ihre Fragen zu lösen, die sich um Web Scraping drehen.
Die Sache ist die, dass Scraping eine komplizierte Aufgabe sein kann, aber mit der Hilfe unserer “Scraping Bots” wird es für jeden Benutzer einfach, jede Art von Daten zu scrapen.
Die in unserer Methodik verwendete Kodierung ist effizient und perfekt implementiert. Wir haben Bots entwickelt, um Daten von Amazon.com zu scrapen, und es ist nicht einfach, hin und wieder Code zu erstellen.
kdnuggets
Die Beziehung zwischen Datenvorverarbeitung und Web Scraping verstehen:
- In vielen Fällen erfordert die Analyse der Benutzerdaten eine Datenvorverarbeitung. Das bedeutet, dass die Daten gründlich analysiert werden, um Inkonsistenzen zu finden.
- Diese Inkonsistenzen hängen von den eingesetzten Methoden und anderen statistischen Projekten ab, durch die die Ergebnisse entstanden sind.
- Die Vorverarbeitung der Daten ist recht komplex. Das bedeutet zwar nicht, dass nur eine Person den gesamten Datensatz verwalten und vorverarbeiten muss, aber es ist viel einfacher, wenn sie es selbst macht.
- Denn wenn viele Personen beteiligt sind, ist es sicher, dass die Arbeitsbelastung für jede Person geringer wird, aber jede Person hat eine andere Herangehensweise an verschiedene statistische Methoden.
- Das bedeutet, dass mit jeder Person, die eine andere Denkweise hat, es einen Unterschied an Meinungen und Perspektiven für jeden der Datensätze, die sie geben, geben wird.
Wenn wir zur Definition der Datenvorverarbeitung springen, ist sie einfach.
Man kann sagen, dass die Datenvorverarbeitung der einfache Akt der Entfernung von unnötigen Daten oder Datenmüll aus dem gesamten Datensatz ist. Der Datensatz kann verschiedene Dinge enthalten, wie z.B. die Beschreibung der Daten selbst oder die Fachinformationen, wie die statistischen Variablen gesetzt wurden oder die Beschreibung der Bedingungen, unter denen sie gesetzt wurden.
Daher ist es notwendig, alle Informationen zu entfernen, die nicht würdig genug sind, um in der Analyse des gesamten Datensatzes zu sein.
Im Folgenden werden wir besprechen, wie Scraping verwendet werden kann, um Daten von den Webseiten zu sammeln und wie sie in ein CSV-Dateiformat gebracht und auf dem lokalen Rechner gespeichert werden können.
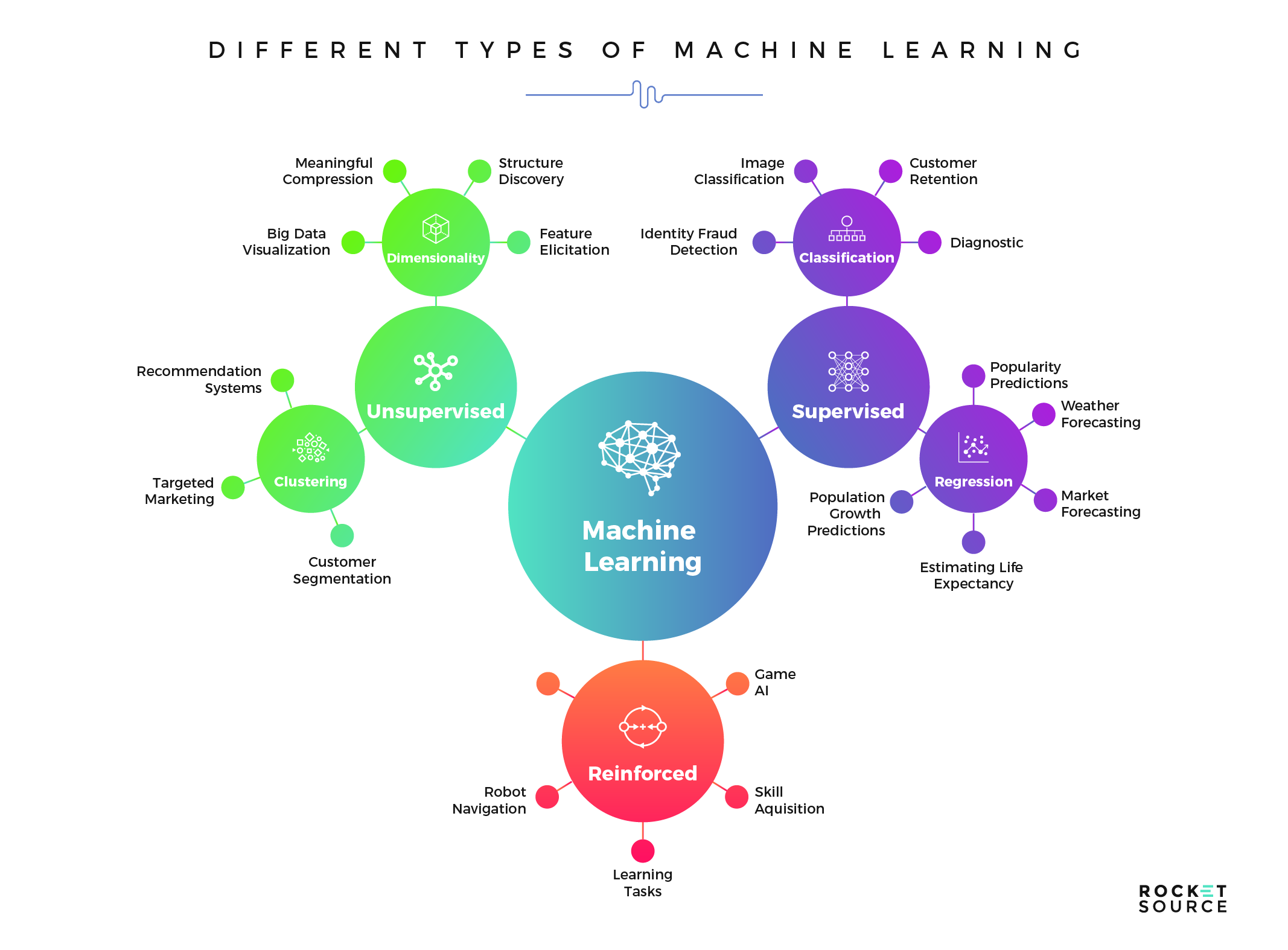
Beim maschinellen Lernen kann man sagen, dass es etwa 7 der wichtigsten Datenvorverarbeitungsschritte beim maschinellen Lernen gibt:
Die sieben Schritte sind:
- Sammeln des Datensatzes.
- Importieren aller Daten und der notwendigen Bibliotheken.
- Der Datensatz wird dann in zwei Teile geteilt: unabhängige und abhängige Variablen
- Die fehlenden Werte werden behandelt.
- Kategoriale Werte werden überprüft.
- Danach erfolgt die Aufteilung des Datensatzes
- Skalierung der Merkmale

Hir Infotech
Aber dies wäre nicht die beste Anleitung, wenn es keine Erklärung gäbe, richtig? Lassen Sie uns zu den Details kommen.
1. Sammlung des Datensatzes :
Web Scraping ist einfach die Extraktion von Daten aus verschiedenen Webseiten und Websites über verschiedene Server, um alle Informationen oder ausgewählte Informationen von der Website zu sammeln.
Normalerweise werden die Daten, die meist nicht auf der Hauptseite vorhanden sind, über einen Link, der auf der Hauptseite angegeben ist, gescraped. Eine der am häufigsten verwendeten Methoden für Web Scraping ist die Verwendung der Programmiersprache Python.
- Während Web Scraping und Pandas beide den gleichen Ansatz zum Sammeln der Daten haben, gibt es ein paar winzige Unterschiede, wie z.B. dass die Anfragen länger dauern, weil sie viele Dateien kompilieren müssen, um Daten aus der Webseite zu extrahieren.
- Der springende Punkt zwischen Pandas und Requests ist jedoch, dass ersteres eine Reihe von verschiedenen Wegen zulässt, auf denen die benötigten Daten entnommen werden können, während Requests das Gleiche auch zulassen, aber durch die direkte Verwendung der URL der Webseite.
- Die Sache ist die, dass es bei Requests keine Einschränkung bezüglich der Vielfalt der URLs gibt, obwohl Requests besser für größere Webseiten geeignet sind.
- Requests sind aufgrund der zunehmenden Komplexität langsamer.
Das ist der Nachteil, den beide Methoden haben, aber das ist etwas, womit jeder Benutzer rechnen sollte, wenn er versucht, moderne komplexe Programmiersprachen zu verwenden, wenn man im allgemeinen Sinne spricht.
Wenn das Ziel des Benutzers jedoch darin besteht, Daten über URLs von Webseiten über verschiedene Server hinweg zu extrahieren, dann ist der Unterschied, den diese beiden Methoden in Bezug auf die Geschwindigkeit haben, durchaus akzeptabel.
Daher sind hier ein paar Tools zusammen mit Bibliotheken, die verwendet werden können:
- BeautifulSoup ist ein großartiges Tool für das Scraping von Informationen über HTML- und XML-Seiten.
- Requests sind für das einfache Senden von HTTP-Anfragen zuständig.
- Schnelle, ausdrucksstarke und flexible Datenstrukturen werden von Pandas bereitgestellt.
2. Importieren aller Daten und der benötigten Bibliotheken :
Hier sind 3 der wichtigsten Bibliotheken, die in der Methode der Datenvorverarbeitung verwendet werden :
- Für Array-Berechnungen in der Programmiersprache Python ist das grundlegende Paket Numpy. Das Einfügen jeglicher Art von mathematischen Operationen oder die Addition von mehrdimensionalen Arrays mit großen Werten oder Matrizen in einen Code kann mit Hilfe dieser Bibliothek durchgeführt werden.
- Matplotlib.pyplot kann beim Plotten verschiedener Arten von Diagrammen in den Code nützlich sein und ist eine 2D-Python-Bibliothek.
- Ein mächtiges und äußerst nützliches Tool, das für die Analyse von Daten zusammen mit dem statistischen Auslesen der Daten verwendet werden kann, ist Pandas. Es ist auch bei der Zeitreihenanalyse sehr hilfreich. Das Importieren und Verwalten von Datensätzen ist auch in diesem Fall sehr wichtig.
3. Der Datensatz wird dann in zwei Teile geteilt: unabhängige und abhängige Variablen :
Im Falle von Machine Learning-Plattformen und -Modellen ist es ziemlich zwingend erforderlich, den Datensatz durch die Extraktion der unabhängigen und abhängigen Variablen zu importieren, und daher ist es zwingend erforderlich, diesen Schritt durchzuführen, um mit dem Web Scraping fortzufahren.
Lassen Sie uns die Datei household_data.csv lesen:
import pandas as pd
df = pd.read_csv('household_data.csv')
print(df)
Item_Category Gender Age Salary Purchased 0 Fitness Male 20 30000 Yes 1 Fitness Female 50 70000 No 2 Food Male 35 50000 Yes 3 Kitchen Male 22 40000 No 4 Kitchen Female 30 35000 Yes
Betrachten wir eine Gleichung, eine wie unten:
y=36a + 94b - 2.5c
Der Wert von y ist abhängig von den Werten von a, b und c. Daher,
- a,b,c: unabhängig
- y: abhängig
So können wir die obige Datei in abhängige und unabhängige Formen aufteilen.
x = df.iloc[:, :-1].values print(x)
Dies ist die Ausgabe, die ein bestimmter Benutzer erhält:
[['Fitness' 'Male' 20 30000] ['Fitness' 'Female' 50 70000] ['Food' 'Male' 35 50000] ['Kitchen' 'Male' 22 40000] ['Kitchen' 'Female' 30 35000]]
Hier sehen Sie, wie Sie die abhängigen Variablen aus dem Datensatz holen können:
y = df.iloc[:, -1].values print(y)
Und voila!
['Yes', 'No', 'Yes', 'No', 'Yes']
4. Die fehlenden Werte werden behandelt:
Modelle für maschinelles Lernen enthalten fehlende Werte im Datensatz und es ist zwingend erforderlich, dass der Benutzer diese fehlenden Werte auf irgendeine Weise entfernt, da sonst das gesamte Web-Scraping umsonst ist.
Die fehlenden Werte in der Architektur des maschinellen Lernens bestehen aus Nullen.
Dies kann erreicht werden durch :
- Löschung einer bestimmten Zeile :
Betrachten Sie eine Spalte, in der der Prozentsatz der fehlenden Werte gleich oder größer als etwa 75 Prozent ist.
Hier ist es also recht einfach, die fehlenden Werte zu entfernen, und zwar durch einfaches Entfernen der Folgezeile dieser Spalte.
Es ist nicht notwendig, dass diese Methode immer zum Erfolg führt, aber sie funktioniert in den Fällen, in denen der Datensatz aus einer Menge von Mülldaten besteht.
- Berechnung des Mittelwerts :
Diese Methode funktioniert besser als die vorherige, aber sie funktioniert in Daten mit einem numerischen Datensatz, und daher kann der Datensatz aus Werten von Gehältern, Mitarbeiternummern, Alter oder anderen statistischen Daten bestehen.Hier wird in der Spalte, in der die fehlenden Werte über 75 Prozent liegen, der Mittelwert, Median oder Modus berechnet und das Ergebnis durch die fehlenden Werte ersetzt.Dies führt dazu, dass die Varianz der Daten zum Datensatz hinzugefügt wird, aber sie ist ziemlich vernachlässigbar, und hier ist, wie :from sklearn.datasets import fetch_california_housing from sklearn.linear_model import LinearRegression from sklearn.model_selection import StratifiedKFold from sklearn.metrics import mean_squared_error from math import sqrt import random import numpy as np random.seed(0) #Fetching the dataset import pandas as pd dataset = fetch_california_housing() train, target = pd.DataFrame(dataset.data), pd.DataFrame(dataset.target) train.columns = ['0','1','2','3','4','5','6','7'] train.insert(loc=len(train.columns), column='target', value=target) #Randomly replace 40% of the first column with NaN values column = train['0'] print(column.size) missing_pct = int(column.size * 0.4) i = [random.choice(range(column.shape[0])) for _ in range(missing_pct)] column[i] = np.NaN print(column.shape[0]) #Impute the values using scikit-learn SimpleImpute Class from sklearn.impute import SimpleImputer imp_mean = SimpleImputer( strategy='mean') #for median imputation replace 'mean' with 'median' imp_mean.fit(train) imputed_train_df = imp_mean.transform(train)
Sie funktioniert gut bei numerischen Datensätzen und wird daher in solchen Fällen bevorzugt. Es gibt zwar auch viele andere Methoden, aber dies ist diejenige, die am häufigsten verwendet werden kann.
5. Kategorische Werte werden geprüft:
Kategorische Werte haben zwei Arten: gekauft und das andere ist das Land. Letzteres hat 3 und ersteres hat 2 Unterkategorien.
Für die Behandlung der unabhängigen Werte, die in den obigen Schritten in die Matrix ‘x’ aufgenommen werden, gehen wir wie folgt vor:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv('household_data.txt')
X = df.iloc[:, :-1].values
y = df.iloc[:, -1].values
labelencoder_X = LabelEncoder()
X[:,0] = labelencoder_X.fit_transform(X[:,0])
X[:,1] = labelencoder_X.fit_transform(X[:,1])
print(X)
So sieht die Ausgabe aus :
[[0 1 20 30000] [0 0 50 70000] [1 1 35 50000] [2 1 22 40000] [2 0 30 35000]]
Als nächstes erfolgt die Kodierung der abhängigen Variablen in der Matrix ‘y’. Dies geschieht mit Hilfe des Lable Encoding wie folgt:
labelencoder_y = LabelEncoder() y = labelencoder_y.fit_transform(y) print(y)
So sieht die korrekte Ausgabe aus:
[1 0 1 0 1]
6. Danach erfolgt die Aufteilung des Datensatzes:
- First of all, there must be a division of the whole dataset into 2 halves, the input, and the output parts.
X, y = data[:, :-1], data[:, -1] print(X.shape, y.shape)
- Thereafter, the dataset can be edited so that about 67% can be used in the training of the model and the rest in rest in testing.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
- Here’s how to implement the dataset in the training procedure :
model = RandomForestClassifier(random_state=1) model.fit(X_train, y_train)
- Thereafter, the user has to fit the model in order to make predictions and evaluate them :
yhat=model.predict(X_test) acc=accuracy_score(y_test,yhat) print('Accuracy: %.3f'%acc)
Hier das gesamte Ergebnis :
(208, 60) (208,) (139, 60) (69, 60) (139,) (69,) Accuracy: 0.783
7. Skalierung der Merkmale :
Die Normalisierung ist eine Skalierungstechnik, bei der die Werte verschoben und neu skaliert werden, so dass sie am Ende einen Wert zwischen 0 und 1 haben. Dies wird als Min-Max-Skalierung bezeichnet.

So funktioniert die Formel für den Prozess, wobei xmax und xmin Minimal- und Maximalwerte sind, und hier ist der Code:
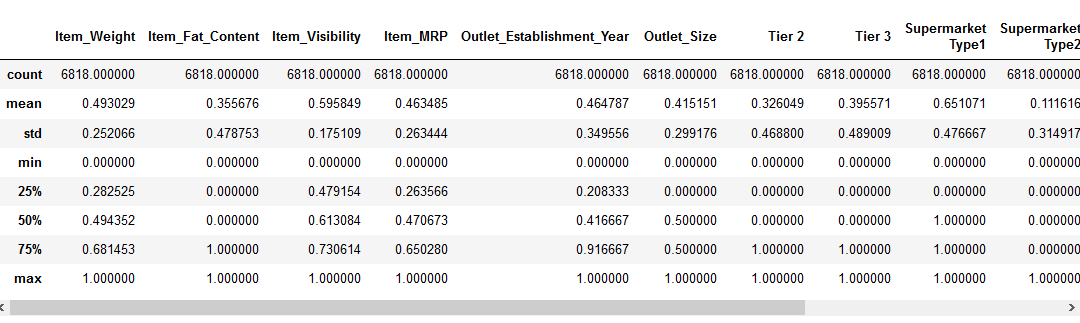
# data normalization with sklearn from sklearn.preprocessing import MinMaxScaler # fit scaler on training data norm = MinMaxScaler().fit(X_train) # transform training data X_train_norm = norm.transform(X_train) # transform testing dataabs X_test_norm = norm.transform(X_test)
So würde die Ausgabe aussehen:
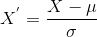
Es ist zu erkennen, dass jeder einzelne Wert zwischen 0 und 1 liegt. Als nächstes kommt die Standardisierung.
Die Standardisierung wird um einen Mittelwert zentriert, der eine Standardabweichung hat. Auf diese Weise wird der Mittelwert aller Attribute zu Null und somit ist die Resultierende der gesamten Verteilung nun Null.
Hier ist die Formel dafür:
Lassen Sie uns einen Blick auf den Code werfen:
# data standardization with sklearn
from sklearn.preprocessing import StandardScaler
# copy of datasets
X_train_stand = X_train.copy()
X_test_stand = X_test.copy()
# numerical features
num_cols = ['Item_Weight','Item_Visibility','Item_MRP','Outlet_Establishment_Year']
# apply standardization on numerical features
for i in num_cols:
# fit on training data column
scale = StandardScaler().fit(X_train_stand[[i]])
# transform the training data column
X_train_stand[i] = scale.transform(X_train_stand[[i]])
# transform the testing data column
X_test_stand[i] = scale.transform(X_test_stand[[i]])
Das Aussehen würde etwa so aussehen:
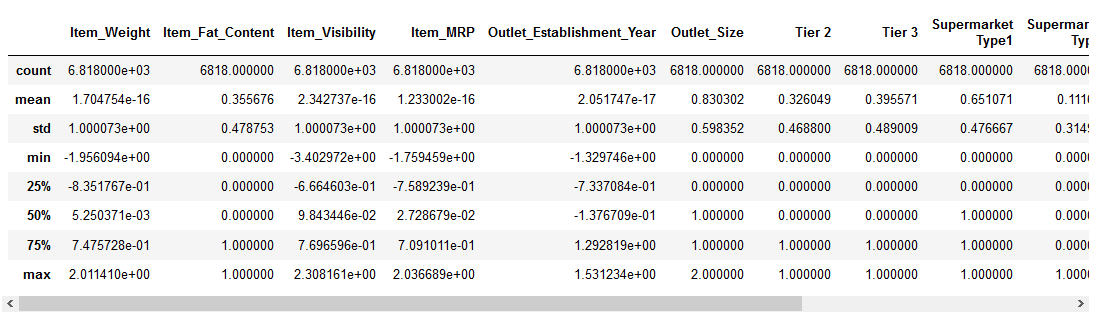
Durch unsere Augen :
So kann Web Scraping im Prozess der Datenanalyse durch Datenvorverarbeitung nützlich sein.
Für den Fall, dass ein Benutzer dies schwierig gefunden hat, werden wir bei de.scrapingpass.com mehr als glücklich sein, Sie mit jeder Art von Web-Scraping bezogene Anfrage zu unterstützen.
Rocketsource
In diesem Leitfaden haben wir sorgfältig die beste und effizienteste Methodik dargestellt, die Sie verwenden können, um das Konzept des Web-Scraping in das maschinelle Lernmodell zu implementieren.
Es gibt zwar viele Anleitungen, die jede Person zur richtigen Methodik führen können, aber dies ist die beste verfügbare. Hier finden Sie alles, was Sie über Web Scraping wissen müssen.



Vivek
More posts by Vivek